An introduction on how Bonial tries not to spam its users
Virtually everyone knows this issue – you were browsing for a new sofa five weeks ago and purchased it recently, but the same sofa is still being recommended to you via an app you’re using or webpages that you’re browsing.
In this blog post, we’re going to outline how you – as a data scientist – can avoid spamming your users with recommendations that they probably don’t want or need anymore.

To achieve this, we’re going to identify features that will help us reach our goal. Furthermore, we will delve into how to develop a recommendation engine using such features, including what Bonial has done. To have a consistent example that will drive you through this post, we will be presenting a use case that can be found at Bonial. In the next section, we’ll describe what Bonial does, and what such a scenario could look like.
What is Bonial?
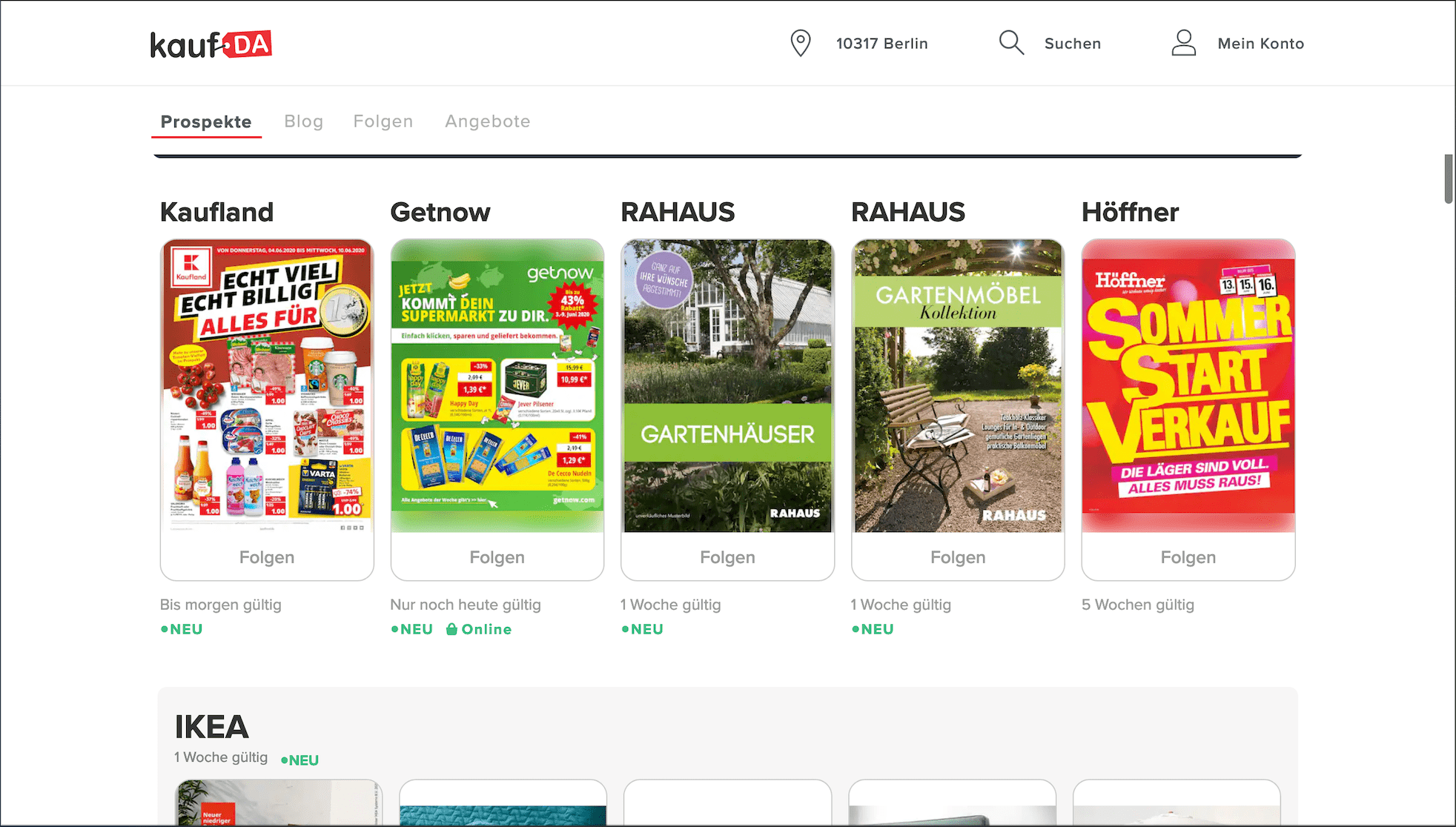
Bonial is a digital advertising partner for offline businesses, such as brick-and-mortar stores or retailers. Shoppers can view advertising content in digital format through mobile and web apps – KaufDa and MeinProspekt in Germany, Bonial in France.
We aim to present only the most relevant advertisements to our users. We ask the user to locate themselves in order to filter relevant content. If location data isn’t available, a user based in Berlin might be recommended a brochure that’s from a store in Munich.
We started breaking down traditional brochures into smaller units called ‘offers’, causing our content to grow. Therefore, we introduced personalized offers in certain features of the app. We wanted to (and continue to) sort the offers in a way that users see the most relevant content for themselves. With this goal in mind, we implemented association rules.
Remember that user who purchased a sofa and is still being recommended the same sofa weeks later? This is how Bonial tackled the issue:
Identify possible features to be used
As a data scientist, you’re aware of many features that can be used in our models, but there are only a few good ones for our use case. Good features for our purpose, are measurements that are likely to change over time. Those measurements are supposed to approximate user interests, who have changed due to a specific event.
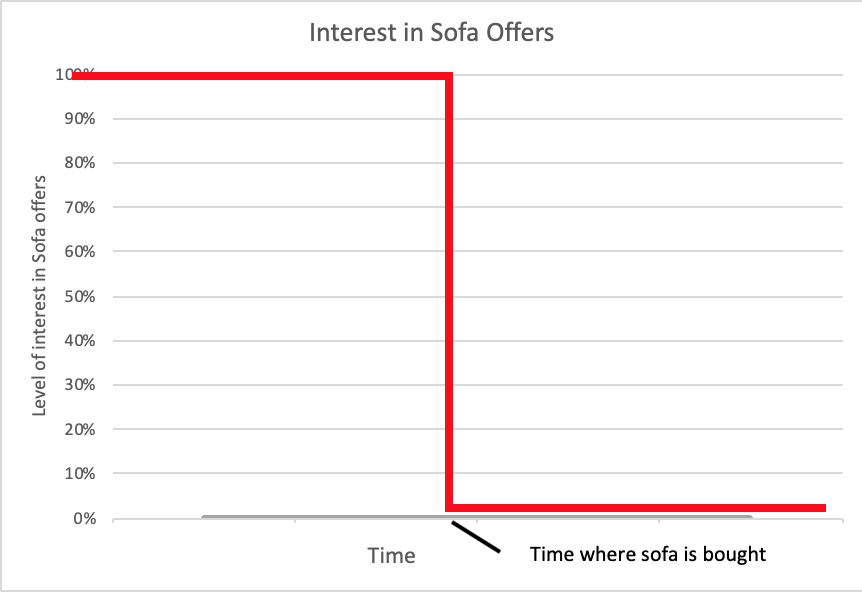
Take our example of the sofa – at first, the user’s need for a sofa is high but once the sofa has been purchased, this interest drops to almost zero. Similarly to Bonial, most companies are not provided with the information about when or if the user purchased the product. Or to put it into a data science context, where the change in the feature variable is occurring. Proxies can be used in your system that could reveal interests, but this will be addressed in the last section.
Bonial has additional challenges on top of this, we have various types of products – electronics, furniture, clothing, and much more. All these product types need to be treated differently.
When designing the features in your case, be careful regarding what makes sense and what doesn’t. If such a feature doesn’t exist, then perhaps your app doesn’t offer a similar use case. The motto should be, “Don’t make up something that isn’t there”.
Develop an interesting recommendation
Now that you’ve gathered the features you need, as well as the type of model you want, you’re ready to start implementing the recommendation system. There should be some type of mechanism that deletes invalid interest regularly so that your model is always fed with the proper user interests. ‘Regular basis’ sounds easier than it actually is.
No one can tell you how frequently this deletion should happen, and this is hardly dependent on your use case. Furthermore, you do not want to throw your system into a cold start situation, deleting all user information and making them appear like a new user.
In the final model, the features can be used in any possible way, but they should be calculated easily. Therefore, we suggest separating the cleaning of the features from the modeling part. Splitting those two parts allows for direct use of the features from your database without the extra effort of cleaning them.

We raised the idea of different treatments in the previous section, that’s something you should take care of during your implementation as well. It’s up to you, whether you want to take care while applying the model or while cleaning the data.
Bonial use case
How does Bonial use all of this in real life? As mentioned earlier, we don’t know exactly when the user bought an item. Furthermore, we have a large variety of products, so purchase cycles are different.
To infer user interests, we simply capture the click of a user on an offer.
As stated earlier, we have different types of products, and in our case, we distinguish three different groups. The groups are namely: short-term, mid-term and long-term goods. Each of these groups is treated differently within our recommendation system. The difference is the time we use them for personalization, let’s explain this in greater detail.
A sofa is an example of a long-term good. Users rarely buy them, let’s say once every other year, so the risk of annoying the user is rather high. Therefore, we only store such clicks for two weeks. If the user is still interested, within two weeks they might make another click, if not, we drop this interest from our model.
Mid–term goods – such as clothes – form the second group. We define this group as goods that are potentially purchased monthly. To remember those interests for longer, we keep clicks on such offers for 30 days.
Short–term goods are the last of our three groups. This is the group of products that are purchased most frequently and therefore we keep this information for 90 days to remember the user interests.
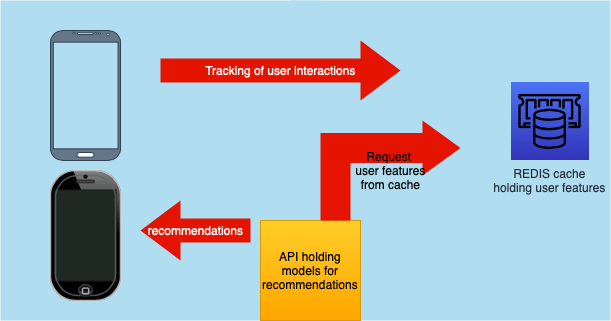
Now that we’ve discussed how Bonial classifies their user interest, we’ll talk about implementation. We use a Redis cache for storing user features, this framework comes in handy as it takes care of deleting keys itself. Within Redis, one can set an expiration date for values stored in the cache. As we track clicks of users, we know when its expiration date is. This date depends on the category of the clicked offer. Therefore, we can set the expiration date directly when entering the key into the cache. Using this technology allows us not to worry about deleting entries at all.
Finally, the model that we use needs to be discussed. Redis was an enabler for us to go the way of real–time predictions, implying that a click of a user now is considered for the next sorting after no longer than thirty seconds. As mentioned, we use association rules – using the interests of users, we infer using their past behavior. This allows us to recommend to one user, offers other users have viewed, who have a similar history.
At Bonial, we have a lot of our code stack for a recommendation in python. Therefore, it was natural for us to implement everything already mentioned in Python as well.
Below, you’ll see a simplified version of how our architecture looks. Naturally, there are many other parts not listed here. For example, an API taking care of A/B-Tests, that we might want to run comparing two sorting models. Parts for filtering for offers in the surrounding user location are also left out.
To give you a feeling of how this works and how much time the entire process requires, please follow along. On every request, we query the Redis cache for the user features and we check which model should be used depending on currently running experiments. Before we can sort any offers, it’s necessary to filter the correct offers to be displayed. The whole process takes around 1 second at most, in the sorting algorithm we must consider around 200 offers each time.
Conclusion
In this blog post, you’ve seen how easy it is to accidentally spam users with outdated information – clearly this is never a desirable outcome. Based on examples from Bonial, we’ve explained an efficient way that one could create and implement a system to prevent this from occurring. There are different use cases for such a system, as well as criteria on how to determine when to stop recommending a certain product group to a user.
Finally, we presented an entire system used at Bonial, that’s capable of minimizing the risk of annoying users. Now it’s up to you to check your user-based features and whether they’re likely to change over time. In the case that you find some – happy coding, and good luck with trying to implement a similar system to the one we’ve presented.

This article was written by Benjamin Mohn, a Data Scientist at Bonial.