

Bitbucket.org is the most commonly used version control repository hosting service at Bonial. It has many features, one of them being their own cloud-based CI/CD system named Bitbucket Pipelines.
In this article, I will share some of the common use-cases that allow our team to automate some critical processes, perform data checks, make our systems stable and resilient, and much more.
Whether you’re using Bitbucket, or you’d like to automate some of your daily tasks, or perhaps you want to learn about life-easing solutions based on Bitbucket pipelines, this article is for you.
Pull request builds and checks
The default pipeline runs on every push to the repository, and that can be especially useful for running checks on the pull-requests in your repository. Apart from the obvious “Does the code in this commit even compile at all?” we run static code analysis on each commit. This is achieved by running a specific sonarcloud-scan pipe, which analyzes the codebase and uploads the results to Sonarcloud.io for further analysis.
It’s possible to run another Sonarcloud pipe, sonarcloud-quality-gate, to fail the entire pipeline if the code quality doesn’t meet the high standards we have at Bonial.
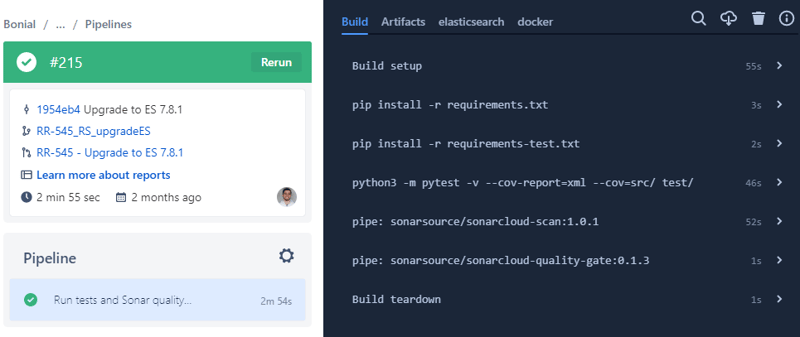
The Bitbucket feature of Sonarcloud integration comes in handy to quickly overview the current code quality status either on the main page of your repository or directly in the pull request.
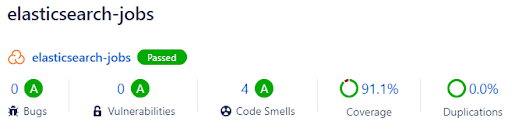
The static code analysis is a big topic and deserves a separate article that will hopefully be published later – stay tuned!
Branch artifact deployment
It is often necessary to update some library code while developing a new feature or fixing a bug in an API. Since library versions are usually fixed in API’s codebase, you would need to update your library, then deploy it to the artifactory, and use the new development version in the component itself.
Performing the library version upgrade and deploying by hand might be cumbersome; that’s why we introduced some branch-specific pipelines to help with this task.
If everyone was deploying a library with the same development version, e.g., 1.01-SNAPSHOT, and several people were working on this library, it would quickly become a mess, since you can’t be sure if this SNAPSHOT version contains your changes or someone else’s.
To resolve these problems, we agreed to name our branches to contain the JIRA code of the ticket you are working on in this branch – e.g., UFP-1234. We also introduced a pipeline that runs on commits in such branches, automatically updates the version, builds the library, and uploads your development artifact of version 1.01_UFP-1234-SNAPSHOT to the artifactory. Voilà! You have your artifact created for your task deployed automatically.
Moreover, it is possible to be notified by Slack regarding the completion of the process. Handy, isn’t it?

API releases
Sometimes you have to release your APIs, in addition to library deployments. This process is slightly more complicated.
- Firstly, you must confirm that the latest build and all the unit and integration tests have passed successfully.
- We usually run the maven-release-plugin to create and push a release version commit and tag to the repository and update the component’s version to the next development iteration version.
- Finally, you have to merge this newly created tag into master and push it to trigger the release Spinnaker pipeline.
There is quite a lot of work there just waiting to be automated! We created a pipeline that performs all these steps without human intervention. This pipeline has to be triggered manually; it checks if the latest build was successful and doesn’t trigger new pipeline runs on an already checked codebase to save some money.
Test automation
Automated tests of our components were introduced a while ago. They usually run as a part of release pipelines. Essentially, these tests check if your API works as intended, querying it as a black box and checking if everything works as it should: GET requests return correct data, PUT requests create entities in the database.
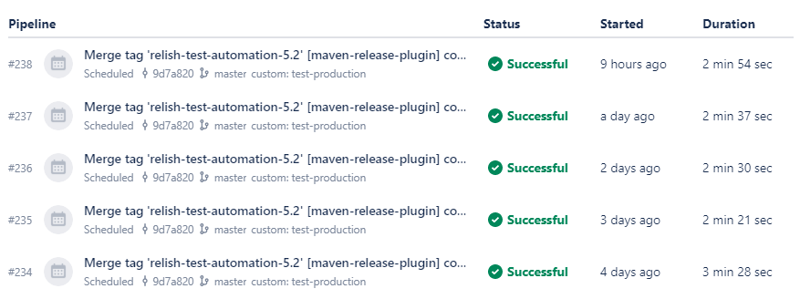
We thought it would be helpful to run these checks as a step in the release process and daily – say, at night, for the developers to see the results in the morning.
It is at this point that the scheduled pipelines feature comes into play. It allows you to set up a scheduled run of a pipeline – hourly, daily or weekly – running it automatically around the time you specified in the settings.
Of course, if some tests have failed, one would want to know what exactly has failed, and for that we have the pipeline artifacts – a subset of files that a pipeline produces to store on Bitbucket servers, which are available for download later.
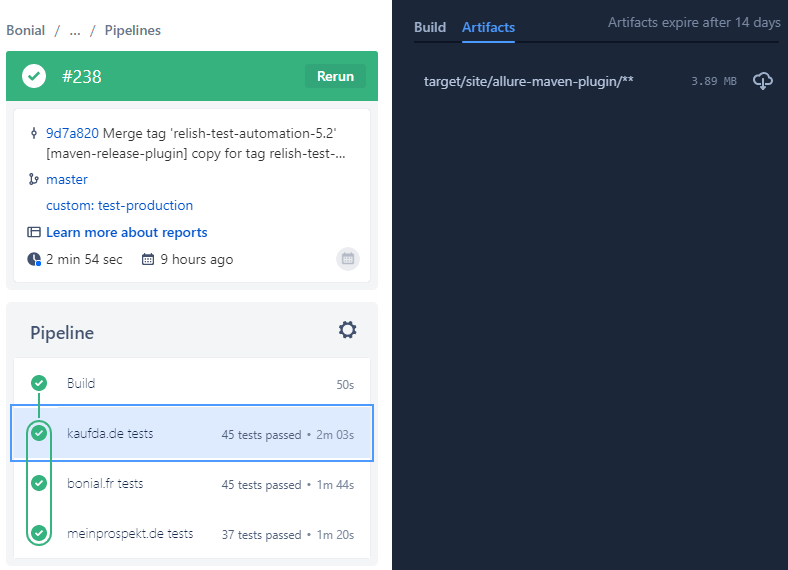
Another cool feature that this pipeline uses is parallel steps, allowing you to run independent steps of a pipeline in parallel to save time before getting the result.
It’s also possible to run a step, run some steps in parallel, and then run some other steps – note that in this pipeline we first build the project and only after that we run three brand-specific sets of tests in parallel.
As with static code analysis, the test automation topic is a whole new world deserving another article. Keep in touch for more interesting stuff!
Production data checks
The APIs require checking, but the production data itself needs to be verified from time to time to be consistent. We introduced several pipelines that run either hourly or daily and check our datasources for any issues.
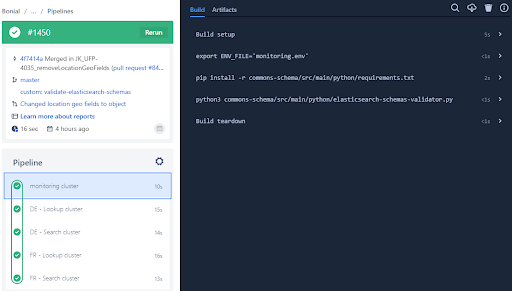
Note that this pipeline also utilizes the parallel steps feature mentioned earlier.
Conclusion
Of course, this is far from everything that can be done, even on the topics covered in the article. More Slack integrations and notifications, smarter pipelines, more to be automated and improved.
I hope this article inspired you to explore the wonderful possibilities of Bitbucket pipelines and try them yourself. If you already use this feature, I hope you discovered some new uses of it.
What’s your experience? Are you already using the Bitbucket pipelines, or have you just planned to? Share your thoughts with us!
Author

This article was written by Arthur Khamitov, a Software Developer at Bonial.


